00. 네트워크 계층의 필요성
물리 계층과 데이터 링크 계층으로는 가까운 영역에서만 통신이 가능합니다.
원거리 통신을 위해서는 다른 영역의 네트워크와 통신을 할 수 있어야 하기에 네트워크 계층이 필요합니다.
01. 네트워크 계층의 개념
- 네트워크 계층은 OSI 7계층 모델의 3번째 계층으로, 다른 네트워크 간의 데이터 전송을 담당하는 계층이다.
- 데이터 패킷을 목적지로 전송하기 위해 경로를 설정하고 이를 통해 패킷이 정확히 전달되도록 보장한다.
- 주요 역할:
- 라우팅(Routing): 패킷을 목적지까지 전달하기 위한 최적 경로를 결정하는 것.
- IP 주소 관리: 송신자와 수신자의 네트워크 주소를 관리하여 데이터가 올바른 위치에 전달되도록 함.
- 패킷 포워딩: 데이터를 적절한 경로를 통해 전송.
02. IP(Internet Protocol) 개요
- 인터넷에서 데이터를 주고받기 위해 사용되는 기본적인 프로토콜로, 네트워크 계층의 핵심 역할을 수행.
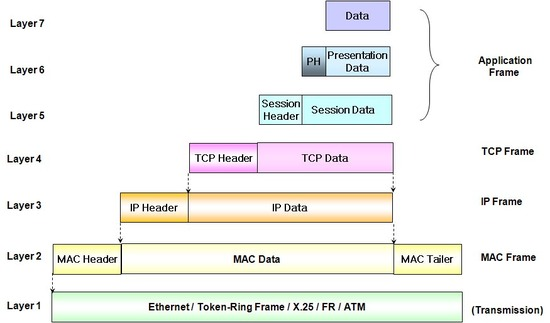
- 데이터는 IP 패킷으로 전송되며, 패킷은 헤더(Header)와 데이터(Data)로 구성된다.
- IP 주소는 호스트에 직접 할당이 가능.
- DHCP(Dynamic Host Configuration Protocol) 프로토콜을 통해 자동으로 할당받거나, 사용자가 직접 할당할 수 있고, 한 호스트가 복수의 IP 주소를 가질 수 있음.
- IP 주소의 사용 기간이 모두 끝나 IP 주소가 DHCP 서버에 반납되면 원칙적으로 이 과정을 다시 거쳐서 IP 주소를 재할당받아야 함.
- IP 주소 임대 기간이 끝나기 전에 임대 기간을 연장할 수도 있음(임대 갱신)
- 하나의 IP 주소는 크게 네트워크 주소와 호스트 주소로 이루어집니다.
- 네트워크 주소 : 호스트가 속한 특정 네트워크를 식별하는 역할
- 호스트 주소 : 네트워크 내에서 특정 호스트를 식별하는 역할
- 네트워크 주소는 네트워크 ID, 네트워크 식별자 등으로 부르기도 하며, 호스트 주소는 호스트 ID, 호스트 식별자 등으로 부릅니다.
- 주요 기능:
- 프래그멘테이션(Fragmentation) : 패킷 분할과 조합: 큰 데이터를 작은 패킷으로 나누어 전송하고, 수신지에서 이를 다시 조합.
- 패킷의 최대 크기 : 네트워크의 MTU(Maximum Transmission Unit)에 맞게 작은 조각으로 분할.
- 조각화된 패킷은 수신지에서 다시 조합.
- 주소 지정: 출발지와 목적지 IP 주소를 패킷에 포함.
- TTL(Time to Live): 패킷의 수명을 제한하여 네트워크 루프를 방지.
03. IPv4와 IPv6
1. IPv4:
- 32비트 주소 체계를 사용하며 약 43억 개의 주소를 제공.
- 주소는 4개의 8비트(옥텟)로 구성되며, 각 옥텟은 0~255의 값을 가짐.
- 주소가 부족해져서 IPv6이 생김.
2. IPv6:
- 128비트 주소 체계를 사용하여 훨씬 더 많은 주소 공간 제공.
- 주소 부족 문제를 해결하고 보안과 네트워크 효율성을 개선.
- 주요 특징:
- 주소 형식: 콜론(:)으로 구분된 8개의 16비트 블록.
- 자동 구성: 기기 자체적으로 주소를 설정할 수 있음.
- 헤더 단순화: IPv4보다 더 단순한 헤더 구조로 처리 속도 향상.
04. IP 주소의 클래스
- 클래스는 네트워크 크기에 따라 IP 주소를 분류하는 기준.
- 클래스풀 주소 체계 : 클래스를 기반으로 IP 주소를 관리하는 주소 체계
- 클래스를 이용하여 필요한 호스트 IP 개수에 따라 네트워크 크기를 가변적으로 조정해 네트워크 주소와 호스트 주소를 구획할 수 있음
- 클래스별 특징
- A, B, C, D, E총 다섯 개의 클래스가 존재.
- A, B, C - 네트워크의 크기를 나누는 데에 실질적으로 사용되는 클래스
- D : 멀티캐스트를 위한 클래스
- E : 특수 목적 클래스
A클래스
- 네트워크 주소의 비트가 0으로 시작, 1 옥텟으로 구성, 호스트 주소는 3 옥텟으로 구성
- A클래스 IP 주소 : 0.0.0.0 ~ 127.255.255.255.
- 맨 앞 옥텟의 주소가 0~127일 경우 A클래스 주소.
B클래스
- 네트워크 주소는 비트 10으로 시작, 2 옥텟으로 구성, 호스트 주소가 2 옥텟으로 구성.
- B클래스 IP 주소 : 128.0.0.0 ~ 191.255.255.255
- 맨 앞 옥텟의 주소가 128~191일 경우 B클래스 주소.
C클래스
- 네트워크 주소는 비트 110으로 시작, 3 옥텟으로 구성, 호스트 주소는 1 옥텟으로 구성.
- C클래스 IP 주소 : 192.0.0.0 ~ 223.255.255.255.
- 맨 앞 옥텟의 주소가 192~223일 경우 C클래스 주소.
예외
※ 호스트 주소가 전부 0이거나 1인 IP 주소는 특정 호스트를 지칭하는 IP 주소로 활용할 수 없다.
0.0.0.0은 해당 네트워크 자체를 의미하는 네트워크 주소로 사용. (ex) 퍼블릭 온라인 DB에 접근할 때)
1.1.1.1은 브로드캐스트를 위한 주소로 사용.
클래스별 네트워크의 크기가 고정되어 있기에 여전히 다수의 IP 주소가 낭비될 수 있는 한계가 있다.
그래서 클래스풀 주소 체계보다 더 유동적이고 정교하게 네트워크를 구성할 수 있는 클래스리스 주소 체계가 등장.
클래스리스 주소 체계
- 클래스 개념 없이 클래스에 구애받지 않고 네트워크의 영역을 나누어 호스트에게 IP 주소 공간을 할당하는 방식
-클래스리스 주소 체계에서는 네트워크와 호스트를 구분 짓는 수단으로 서브넷 마스크(Subnet mask)를 이용.
05. IPv4 주소 구조와 서브넷 마스크
1. IPv4 주소 구성:
- 네트워크 부분(Network Portion): 네트워크를 식별.
- 호스트 부분(Host Portion): 네트워크 내의 특정 장치를 식별.

2. 서브넷 마스크(Subnet Mask):
- 서브넷 마스크(Subnet Mask)는 IP 주소상에서 네트워크 주소는 1, 호스트 주소는 0으로 표기한 비트열을 의미
- 서브네팅 : 네트워크 성능 보장, 자원을 효율적으로 분배하기 위해 네트워크 영역과 호스트 영역을 쪼개는 작업
- 네트워크와 호스트 부분을 구분하기 위한 32비트 값.
ex)
- IP 주소: 192.168.1.1
- 서브넷 마스크: 255.255.255.0
- 네트워크 주소: 192.168.1.0
- 호스트 주소: 특정 장치를 식별.
3. 프리픽스 표기법:
- 네트워크 비트의 길이를 `/n` 형태로 표시. (예: 192.168.1.0/24)
A, B, C 클래스의 기본 서브넷 마스트
-서브넷 마스크 는 IP 주소와 서브넷 마스크를 비트 AND 연산하여 네트워크 주소와 호스트 주소를 구분 짓습니다.
-서브넷 마스크를 표기하는 방법 2가지
1) 255.255.255.0 처럼 10진수로 직접 표기하는 방법
2) IP 주소/서브넷 마스크 상의 1의 개수로 표기하는 방법
- CIDR(Classless Inter Domain Routing Notation)
- IP 주소와 서브넷 마스크를 함께 표현할 수 있는 간단한 표기로 많이 활용함.
06. 서브넷 마스크랑 IP클래스의 차이점
IP 클래스
- 네트워크의 크기와 범위를 나타내는 초기 설계 방식.
- 기본 서브넷 마스크와 관련이 있습니다.
- (예: A 클래스는 기본적으로 255.0.0.0 서브넷 마스크를 사용)
서브넷 마스크
- 네트워크를 더 작은 서브넷으로 나누기 위해 사용하는 도구.
→ 고정된 클래스 방식(A, B, C)을 유연하게 넘어서, 더 세분된 네트워크를 만들 수 있습니다.
※ 현재는 CIDR(Classless Inter-Domain Routing)라는 방식을 사용하며, IP 클래스 개념은 사실상 잘 사용되지 않습니다.
CIDR에서는 서브넷 마스크를 기반으로 네트워크를 구분합니다.
(예: 192.168.1.0/24에서 /24는 서브넷 마스크 255.255.255.0을 의미)
07. IPv4 패킷 구조 - 헤더 필드 구성

1. 버전(Version) : IP 버전(IPv4는 4)을 나타냄.
2. 헤더 길이(Header Length ): IP 헤더의 크기(단위: 4바이트).
3. 서비스 유형(ToS) : 데이터 전송 우선순위 및 서비스 품질.
4. 패킷 전체 길이(Total Length) : 헤더와 데이터 포함 총 크기(최대 65,535바이트).
5. 식별자(Identification) : 패킷에 할당된 번호 .
데이터 분할 시 각 조각의 ID(수신지에서 패킷 재조합 시 사용).
6. 플래그(Flags) : 패킷 분할 여부.
플래그는 총 세 개의 비트로 구성된 필드.
첫 번째 비트는 항상 0으로 예약된 비트로 현재는 사용되지 않음.
DF(Don’t Fragment) 비트 : 이름 그대로 단편화를 수행하지 말라는 표시.
0 : IP 단편화가 가능합니다.
1 : IP 단편화를 수행하지 마라
MF(More Fragment) 비트 : 단편화된 패킷이 더 있는지의 여부를 나타냄.
0 : 패킷이 마지막 패킷임
1 : 쪼개진 패킷이 아직 더 있음.
7. 프래그먼트 오프셋(Fragment Offset) : 조각의 순서를 표시.
단편화되기 전에 패킷의 초기 데이터에서 몇 번째로 떨어진 패킷인지를 나타냄.
단편화되어 전송되는 패킷들은 수신지에 순서대로 도착하지 않을 수 있기에 수신지가 패킷들을 순서대로 재조합하려면 단편화된 패킷이 초기 데이터에서 몇 번째 데이터에 해당하는 패킷인지 알아야 합니다.
8. TTL(Time to Live) : 패킷이 네트워크에서 유지될 수 있는 최대 수명(홉수).
패킷이 하나의 라우터를 거칠 때마다 TTL이 1씩 감소하며 TTL 값이 0으로 떨어진 패킷은 폐기됨.
TTL 필드의 존재 이유는 무의미한 패킷이 네트워크상에 지속적으로 남아 있는 것을 방지하기 위함.
※ 홉 : 패킷이 라우팅 도중 호스트와 라우터 간에 혹은 라우터와 라우터 간에 이동하는 하나의 과정
패킷은 여러 홉을 거쳐 라우팅 될 수 있다.
9. 프로토콜(Protocol) : 상위 계층 프로토콜(TCP: 6, UDP: 17 등) 식별.
10. 헤더 체크섬(Header Checksum) : 헤더 오류 감지.
11. 출발지/목적지 주소(Source/Destination Address) : 송신자와 수신자의 IP 주소.
12. 옵션 및 패딩(Options/Padding) : 확장 가능 정보 및 정렬.
13. ARP(Address Resolution Protocol) 프로토콜
- 상대 호스트의 IP 주소는 알지만, MAC 주소는 알지 못하는 경우 사용.
- ARP는 IP 주소를 통해 MAC 주소를 알아내는 프로토콜로 동일 네트워크 내에 있는 송수신 대상의 IP 주소를 통해 MAC 주소를 알아낼 수 있다.
- 동작 과정
브로드캐스트 요청 → 응답 → ARP 테이블 저장
- 통신하려는 대상이 다른 네트워크에 있다면, ARP는 라우터의 MAC 주소도 알아내는 과정을 거칩니다.
데이터를 라우터로 전달 → 라우터는 목적지 네트워크로 다시 데이터를 전달.
각 네트워크마다 ARP 요청/응답 과정을 반복.
- 네트워크 트래픽 최적화와 보안 위협 방지를 위해 ARP의 작동을 이해하고 적절한 설정이 필요합니다.
식별자, 플래그, 단편화 오프셋 필드는 IP 단편화 기능에 관여하고, 송신지 IP 주소, 수신지 IP 주소는 IP 주소 지정 기능에 관여함.
08. 라우팅(Routing)
- 네트워크 계층의 핵심 기능으로, 목적지까지의 최적 경로를 선택하여 패킷 전달.
- 내 컴퓨터 ~ 구글의 웹 페이지를 보내 주는 호스트에 이르기까지의 경로 보기
tracert http://www.google.com
traceroute http://www.google.com
1. 라우터(Router):
- 서로 다른 네트워크를 연결하며, 패킷을 목적지로 전달하기 위해 라우팅 테이블을 참조하는 장치 .
ex) 공유기
- 라우터의 내부 구성요소 4가지
- input port (입력 포트)
- output port (출력 포트)
- switching fabric (스위칭 구조)
- routing processor (라우팅 프로세서)
2. 라우팅 방식:
정적 라우팅:
- 관리자가 수동으로 경로를 설정.
- 소규모 네트워크에 적합하지만, 대규모 네트워크에서는 비효율적.
동적 라우팅:
- 네트워크 상태에 따라 경로를 자동으로 설정 및 갱신.
- 사용 프로토콜: RIP, OSPF, BGP 등.
3. 동적 라우팅 알고리즘:
- 거리 벡터 알고리즘(Distance Vector):
인접 라우터와 경로 정보를 주기적으로 교환.
- 단점: 느린 수렴 속도, 루프 발생 가능.
- 링크 상태 알고리즘(Link State):
전체 네트워크 구조를 기반으로 최적 경로 계산.
이벤트 기반으로 동작하여 효율성 증가.
4. 라우팅 종류
- 코어 : 랜이나 다수의 ISP 네트워크나 통신사와 같은 인터넷 제공자(ISP)의 네트워크를 서로 연결한다.
- 센터 : 회사의 본점과 지점을 연결시킨다(WAN), 인터넷 제공자와 기업의 네트워크를 연결한다.
- 원격 : 랜과 WANG을 연결한다.
- 브로드밴드 : 브로드밴드 수준의 인터넷에 접속할 때 쓰이는 라우터, 가정이나 소기업에 사용된다.
- 핫스폿 : 우리의 핸드폰처럼 휴대용 핫스폿에서 인터넷을 접속하는 데에 쓰이는 라우터.
- ISP : 인터넷을 제공하는 사람이 쓰는 라우터다.
※디폴트 게이트웨이(Default Gateway): 내부 네트워크에서 외부 네트워크로 데이터를 전달할 때 사용하는 기본 경로.
추가 과제
인터넷에 네이버를 검색하면 네트워크에서 발생하는 일을 검색해보고 관련 내용을 학습해보세요.
웹브라우저의 통신 방식
1️⃣ 사용자가 웹 브라우저의 주소창에 URL을 입력
2️⃣ 웹 브라우저는 입력받은 URL을 DNS 서버로 전달하여 해당 IP 주소를 탐색
3️⃣ DNS 서버는 도메인 이름을 IP 주소로 변환
4️⃣ 웹 브라우저는 해당 IP 주소로 HTTP 요청을 전달
5️⃣ IP 주소에 연결된 웹 서버는 요청(Request)을 받아 처리
6️⃣ 웹 서버는 처리 결과를 HTTP Response로 브라우저에게 전달
7️⃣ 웹 브라우저는 받은 HTTP Response을 바탕으로 사용자에게 페이지를 표시

주소창에 "naver.com"을 입력하고 엔터를 누르면 일어나는 과정
1️⃣ 주소창 입력 및 해석 :
사용자가 'naver.com'을 주소창에 입력하고 엔터를 누르면 브라우저는 입력값이 URL인지 검색어인지 판단한다.
- URL : 네트워크 호출을 해서 해당 URL에 맞는 데이터를 받아옴.
- 검색어 : 기본 검색 엔진을 통해 검색 결과 페이지로 이동.
(이 경우 'naver.com'은 URL이므로 네트워크 호출이 진행됩니다)
2️⃣ 네트워크 호출
1. 네이버 서버의 주소를 알기 위한 네임 서버(name server) 와 통신
2. 알아낸 주소로 네이버 서버와 통신하여 원하는 데이터 받기
1. DNS 조회 및 IP 주소 확인
- 브라우저는 OS 캐시나 로컬 'host' 파일에서 IP 주소를 찾음.
- 없다면 DNS 서버에서 IP 주소 찾기.
네임 서버가 도메인 주소에 대응하는 IP 주소를 찾아준다.
클라이언트는 'naver.com'에 해당하는 IP 주소를 요청하고 응답받을 수 있다.
2. 네이버 서버와 통신
1) TCP 3-Way Handshake :
- 클라이언트와 네이버 서버 간 연결 확인 과정을 거칩니다.
(1) Client → Server : TCP SYN 패킷을 서버에 보내 connection 요청
(2) Server → Client : TCP SYN ACK으로 응답
(3) Client → Server : TCP ACK 패킷을 보냄
2) HTTP 요청 전송:
- 브라우저가 서버에 HTML, CSS, JavaScript 등의 리소스를 요청합니다.
3) 서버 응답
- 네이버 서버는 요청에 따라 HTTP 응답 메시지를 브라우저로 전달하며 필요한 리소스를 반환합니다.
- HTTP Response 포함 정보:
- Browser가 요청한 웹 페이지
- Status Code(현재 Response의 상태)
- Compression Type(Content-Encoding, 인코딩 방식)
- Cache-Control(페이지 캐싱 방법)
- (설정할 Cookie가 있다면) Cookie
- 개인 정보
3️⃣ 렌더링(화면 출력)
1. 렌더링 프로세스
1) HTML 문서 파싱해 → DOM 트리 구축
※ 파싱 (Parsing) : 문자 스트림을 브라우저가 이해할 수 있는 트리구조로 변환하는 과정
2) CSS 파싱 → CSSOM 트리 구축
중간에 < script > 태그 만나면 DOM 생성을 중단하고
JS파싱 → 추상 구문 트리(AST) 를 생성하고 이를 바이트 코드로 변환해 실행 → 다시 DOM 생성 )
DOM 조작 에러 위험을 방지하기 위해 script 태그는 body 태그의 가장 아래 위치해야 한다.
3) DOM 트리와 CSSOM 트리를 결합해 Render Tree를 생성합니다.
랜더트리 생성 과정
html 태그, body 태그를 처리해 랜더 트리 루트를 구성
DOM 의 최상위 노드부터 순회하며 화면에서 보이지 않는 노드는 구성에서 제외
화면에 보여지는 나머지 노드에 CSS DOM 규칙에 일치하는 CSS style 적용

2. 레이아웃 및 페인팅
1) 레이아웃(Layout) : 렌더트리 배치
- Render Tree를 기반으로 요소의 위치와 크기를 계산합니다.
- 글로벌 레이아웃
- 전체적인 배치 과정이 필요한 경우 발생.
- ex) 초기 레이아웃 발생 시, 폰트나 전역 스타일 변경, 창 크기 리사이즈
- 리플로우(Reflow) : 초기 배치 이후 다시 레이아웃 작업이 이루어지는 과정.
- 로컬 레이아웃
- 초기 레이아웃 이후 특정 DOM 노드에 변경이 생길 때 발생.
- 필요한 부분만 재배치하여 전체 배치 과정의 불필요한 낭비를 줄임.
2) 페인팅(Paint) : 렌더트리 그리기
- 래스터화 (Rasterizing) : 렌더트리의 각 노드를 화면에 픽셀 단위로 그려줍니다.
- 리패인트(Repaint) : 페인트 과정이 끝나고 브라우저에서 특정 변경 사항이 생겨 다시 페인트를 하는 과정.
추가 : FE/BE 관점
프론트엔드 관점
- 유저 인터페이스: 사용자가 요청한 페이지를 브라우저에 적절히 표시하는 역할.
- 렌더링 최적화: 데이터를 받아오는 속도 및 화면 표시 성능 개선이 중요합니다.
백엔드 관점
- 데이터 처리 : 클라이언트의 요청을 받아 필요한 리소스를 적절히 가공해 응답합니다.
- 보안 및 속도: 데이터의 무결성과 효율적인 전송 속도를 보장해야 합니다.
참고
1. https://carpediem9911.tistory.com/1
2. https://ascentoptics.com/blog/ko/types-of-routers/
5. https://aws-hyoh.tistory.com/70
7. 웹브라우저의 통신 방식 : https://teamsparta.notion.site/1-1-HTTP-997a694608b340efaaa85c413434dd40
'내일배움캠프_게임서버(202410) > 분반 수업 스텐다드' 카테고리의 다른 글
| 스텐다드 241211 (0) | 2024.12.11 |
|---|---|
| 데이터 링크 계층 발제 (2) | 2024.12.11 |
| 스텐다드 241209 (2) | 2024.12.09 |
| 스텐다드 OSI 2계층 데이터 링크 계층 조사 (0) | 2024.12.09 |
| OSI 3계층 네트워크 계층 (0) | 2024.12.09 |


