컴퓨터 구조 발제
https://velog.io/@nuketuna/TIL-20250106-TIL-CA-Hardware-1-Processor
🔷 프로세스 측면에서 보는 컴퓨터 구조, CPU
Processor : Control 유닛 + Datapath 유닛
🔹 Input
Input 유닛은 Memory에 데이터를 쓴다
ex. 마이크 (음성 입력), 키보드 (키 입력)
🔹 Output
Output 유닛은 Memory 에서 데이터를 읽는다.
ex. 스피커 (음성 출력), 모니터 (화면 출력)
🔹 Memory
ex. Main memory, secondary memory
🔹 Control
Control 유닛은 컴퓨터 내부의 명령을 해석 및 실행하는 역할로 명령에에 따라 데이터패스, 메모리, 입출력의 동작을 결정하는 신호를 보낸다
ex. PC (Program Counter),
🔹 Datapath
Datapath는 데이터를 세이브/로드하는 역할 및 연산 수행을 담당
🔷 CPU (Central Processing Unit)
CPU 는 중앙 처리 장치로, 메모리에 저장된 명령어를 읽어들이고, 읽어들인 명령어에 대한 interpret(해석)와 implement(구현)를 담당한다.
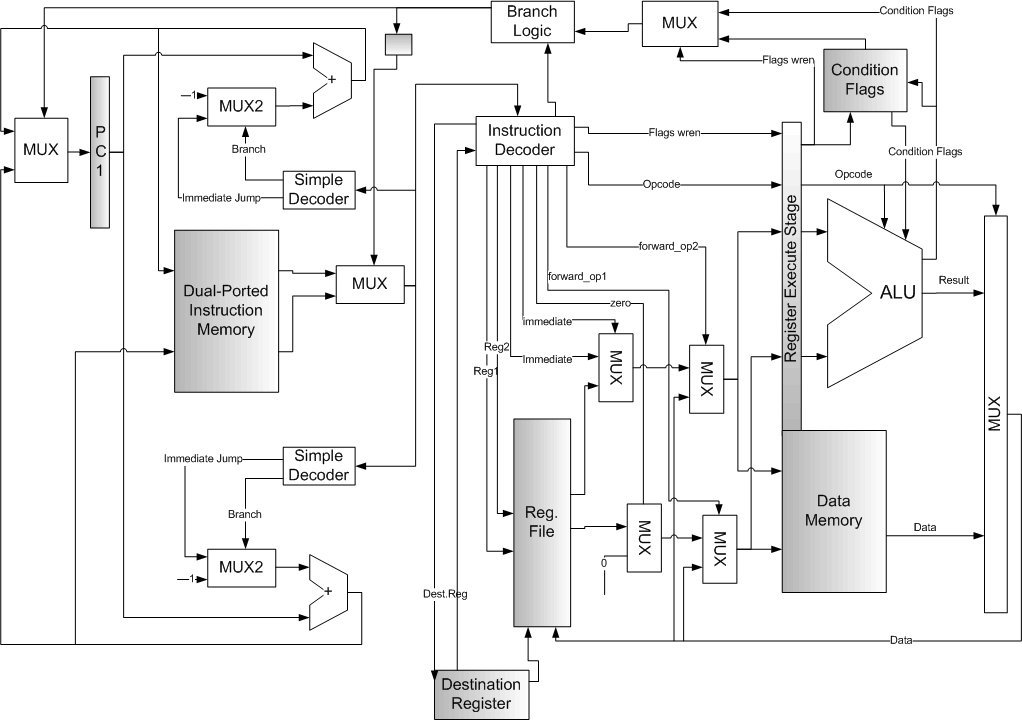
🔹 ALU (Arithmetic Logic Unit)
ALU는 산술 연산 (덧셈, 뺄셈, 곱셈, 나눗셈)과 논리 연산 (AND, OR, NOT, XOR) 을 수행하는 연산 장치이다.
🔹 CU (Control Unit)
CU는 산술 연산 (덧셈, 뺄셈, 곱셈, 나눗셈)과 논리 연산 (AND, OR, NOT) 을 수행하는 연산 장치이다.
🔹 Register
Register는, clock을 공유하는 n개의 Flipflop으로 구성되어 n개의 비트를 통해 binary 정보를 저장하는 장치이다.
바이너리 같은 저장 장치.
cf. FlipFlop
전자 회로에서 1bit 정보를 저장하는 기억 소자
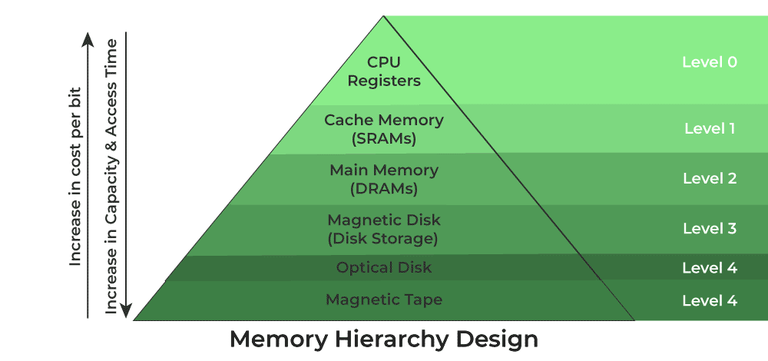
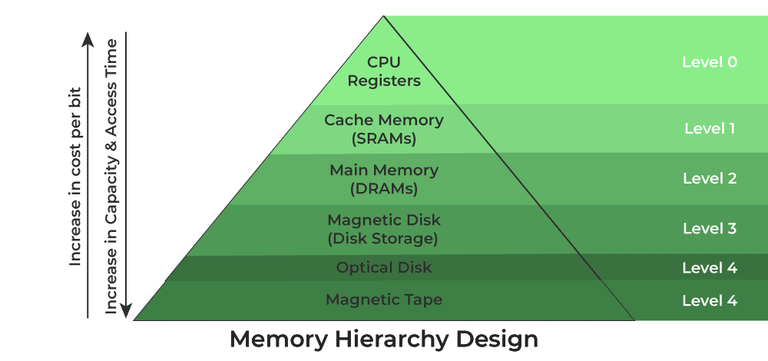
🔹 Cache
Cache는 CPU와 RAM 메인 메모리 사이 데이터 전송 속도를 높이기 위해 사용되는 고속 저장장치이다.
CPU는 Instruction Cycle을 통해 (Fetch -> Decode -> Execute -> Store) 다음과 같은 단계를 거친다.
🔷🔹🟦💠◇◆◈♢
🚫❌ ❓❔? ⁉
🔗🔨⚒️⛏🔧🔩🗜🛠🧰🧲⚙️⛓🪓🦯🪚🪛🪝🪜
LOAD 15
ADD 57
STORE RESULT
1) Fetch Instruction
CPU는 메인 메모리에서 코드 데이터를 읽어오며, 위 instruction들에 대해 PC가 첫 번째 명령어 LOAD 15를 가리킨다. 해당 명령어를 Instruction Register에 가져오고, PC는 다음 명령어를 처리할 수 있게 증가한다.
2) Decode Instruction
Instruction Decoder가 처리할 명령어에 대해 해석 과정을 거친다. 명령어 LOAD 15에 대해, Operator인 LOAD는 적재 명령어임을 해석하고, Operand인 15는 메모리에서 가져와 Register에 저장한다.
3) Execute Instruction
앞서 decode된 내용을 바탕으로 작업을 수행한다.
LOAD 15에 경우, decode된 내용은 적재, 15이므로 accumulator에 15를 저장한다.
4) 다시 Fetch
PC가 앞선 fetch과정에서 증가했기에, 두 번째 명령어인 ADD 57 명령어를 가리킨다. 이 명령어를 가져오고, PC는 다시 증가한다.
5) Decode Instruction
명령어 ADD 57에 대해, Operator인 ADD 덧셈 산술 연산 명령어임을 해석하고, Operand인 57 메모리에서 가져와 Register에 저장한다.
6) Execute Instruction
ADD 57의 경우, decode된 내용은 덧셈 산술 연산, 57이므로 accumulator에 저장된 값 (15)에 메모리에서 가져온 피연산자 57에 대한 산술 연산을 처리하여 결과값(72)을 다시 accumulator에 저장한다.
7) Store
accumulator에 저장된 계산 결과를 메모리 위치에 저장한다. 앞서서 from memory to register의 방향으로 처리한 load 적재와 반대로, store 저장은 register에서 memory로 데이터를 보낸다.
양자 모두 CPU 내부에서 데이터를 저장하는 메모리 역할을 하지만 그 용도와 작동 방식은 다르다.
register의 경우,
CPU 내부에 직접 사용되는,
매우 빠른 처리 속도의
연산에 필요한 소량의 데이터/주소를 일시적으로 저장하는 역할을 한다.
cache의 경우,
main memory 와 CPU 사이 위치한
최근에 사용/ 빈번하게 사용되는 데이터를 빠른 접근을 위해 저장하여
main memory 접근 시간을 줄임으로 성능을 향상시키는 역할을 한다.
이미지 :
https://velog.velcdn.com/images/nuketuna/post/6a9822ff-e824-4ae4-8957-0abe3b5fb60e/image.png
cf. Pipelining
모든 명령어가 같은 길이의 클럭 사이클을 가지게 된다면 단일 사이클 설계만으로 처리가 수월하겠지만, 부동소수점 유닛을 포함한 복잡한 명령어 집합에 대해서는 한계가 있다.
이러한 단일 사이클 구현은 Common Case Fast라는 설계 원칙에 위반되기 때문에, 여러 명령어가 중첩되어 실행되는 구현 기술인 Pipelining을 보편적으로 사용한다.
ex. 앞선 시나리오에서 예를 들면,
단일 사이클이라면,
첫 번째 명령어 LOAD 15 의 처리 사이클을 마친 이후
두 번째 명령어 ADD 57 에 대해 수행될 것이다.
파이프라이닝을 적용하면,
첫 번째 명령어 LOAD 15 의 Decoding 이후,
LOAD 15의 Execution을 처리하면서 동시에 ADD 57을 Decoding하고, 다음 명령어를 가져올 수 있다.
Pipelining은 적용하면
cycle time 자체를 단축시키지는 못하나
throughput을 증가시킴으로 병령 처리를 통해 전체 명령어 집합 처리 시간을 단축시킨다.
3. 성능 측정 performance
성능 예시
개개인 유저 입장에서
Response Time 응답시간으로서의 요청을 보낸 시점부터 응답이 도착하기까지 걸리는 시간,
Execution Time 실행시간으로서 프로세스 관점에서 전체 작업 개시에서 종료까지의 시간이 성능 측정 척도.
시스템 관리자
단위 시간당 완료하는 태스크의 수와 관련한 Bandwidth나 Throughput이 중요할 것이다.
1. Clock Cycle
클록 사이클은 하나의 클록 주기를 의미하며, 시스템의 클록이 한 번 완전히 변하는 시간이다.
클록 사이클은 CPU나 다른 디지털 시스템에서 동작을 정기적으로 동기화하는 기준이 된다.
간단히, positive edge에서 다음 positive edge까지 걸린 시간이다.
2. Clock Speed / Clock Rate
클록 속도는 시스템 클록의 주파수로, 1초 동안 클록 사이클이 얼마나 발생하는지를 나타냅니다. 측정 단위로 Hz(헤르츠)가 사용되며 초당 발생하는 클록 사이클 수를 의미한다.
(clock rate는 cct의 역수 관계)
단위 시간 동안의 positive edges의 수를 의미한다.
cf. Positive Edge
Positive Edge는 clock signal이 낮은 상태에서 높은 상태로 변화할 때 발생하는 ( 0 -> 1) 상승 엣지 순간을 의미한다.
예를 들어, flipflop이나 register 같은 순차 회로는 positive edge에서 데이터를 읽거나 저장한다.
고전적인 CPU 성능 식
CPU 시간 = Instruction 개수 * CPI (Clock cycles per Instruction) * Clock Cycle Time
cf. cpu와 관련하여 알면 좋을 CA 쪽 지식들
설계철학 관련
ISA (Instruction Set Architecture)
ISA, 명령어 집합 구조란 CPU가 이해하고 실행하는 명령어 집합 및 인터페이스를 정의한 추상적 모델이다.
어셈블리 기계어 단의 low level의 하드웨어와 high level단(사용자와 가까움)의 응용의 소프트웨어 간의 인터페이스를 정의하는 명령어 집합이다.
예시)
종류: Intel사의 x86, AMD사의 AMD64(x86-x64), ARM사의 ARM ISA, MIPS, AVR, etc.
x86
Intel 사가 설계한 x86 은 복잡한 명령어 셋으로 높은 성능과 다양한 sw를 지원하지만 높은 전력 소모가 발열에 문제점을 가지고 있다. 명령어 집합으로는 CISC를 택했으며, 16bit / 32bit을 사용한다.
MIPS
MIPS는 RISC 기반의 ISA로 단순한 명령어 셋과 고효율적인 설계로 전력 소모와 발열이 상대적으로 적은 장점을 가졌기에 embedded, IoT, 네트워크 장치 등에 널리 사용된다.
CPU 설계 철학: RISC와 CISC
CISC (Complex Instruction Set Computing)
CISC는 복잡하고 다양한 명령어를 포함한 CPU 설계 철학으로, 고급 명령어를 제공하며 SW에 가깝게 high level단으로 프로그래머의 편의성에 초점을 둔 설계 방식이다.
설계 방식에서의 가장 큰 특징은 복잡한 명령어의 개수가 많다는 점이다.
(+) 장점
프로그래머에게 편함
컴파일 과정이 쉽고 sw친화적 명령어로 인해 호환성이 좋다.
복잡한 작업에 대해 단일 명령어로 처리 가능하다.
다양한 주소 지정을 지원하고, sw 개발에 보다 용이하다.
(-) 단점
가변적인 명령어 길이로 하드웨어 설계와 decoding 과정이 복잡하다.
위의 이유로 전력 소모 및 발열이 높다.
모바일 환경 혹은 저전력 기기에 적합하지 않다.
복잡성이 높은 만큼 파이프라이닝 설계가 어려워 처리/실행 속도가 상대적으로 느리다.
RISC (Reduced Instruction Set Computing)
RISC는 간소화된 명령어 집합을 포함한 CPU 설계 원칙으로, HW에 가깝게 Low level 단으로 고효율 고성능의 하드웨어 설계에 초점을 둔 설계 방식이다.
다음과 같은 장단점을 가진다.
(+) 장점
명령어가 간단한 형식과 단순화된 종류를 가진다.
명령어가 고정 길이이기 때문에 decoding 과정이 단순하고 빠르다.
대부분의 명령어가 동일 clock cycle안에서 실행된다.
메모리 접근 및 cache 활용이 효율적이다.
단순한 명령어로 인해 병렬 처리가 수월하고 파이프라이닝 성능이 극대화된다.
단순한 설계로 전력 소모와 발열이 적은 편이다.
(-) 단점
복잡한 작업을 처리하는 데에 더 많은 명령어가 필요하다.
명령어가 하드웨어 적이며 처리 비트 단위가 변하거나 프로세서 구조 변경 시 하위 프로세서와 호환성이 떨어진다.
_______________________________________________________________
발제 2
시스템버스
제어버스
2. 내부버스
3. ...
CPU의 명령어 이해
연산코드
명령어가 수행할 연산에 대한 정보
오퍼랜드
피연산자의 메모리 위치가 담김
CPU
ALU (Arithmetic Logic Unit) - 산술논리연산장치
연산 수행
CU (Control Unit) - 제어장치
명령 해석
감독 같은 것
Register - 레지스터
임시저장장치
ALU
레지스터
프로그램 카운터
다음으로 사용할 명령어를 미리 찾아둠
2.메모리 주소 레지스터
메모리 가기전에 서침. 제일 먼저 사용
명령어 실행에 필요한 주소 정보 저장
3.메모리 버퍼 레지스터
4.명령어 레지스터
실행 중 사용하는 정보 가지고 있음
5. 플래그 레지스터
6. 스텍 포인트
7. 베이스 레지스터
CPU 동작
CPU 성능 관련 개념
클럭
명령어 병렬 처리 기법
명령어 파이프 라인
인출-해석-실행-저장
파이프라인은 뭔가를 동시에 실행 하는 것
_________________________________________________________________
수업
이전 수업 :
https://ashen99.tistory.com/527
https://teamsparta.notion.site/4737d3fd0c434ca5b4b000bbfa2ce737#dff8c4d6851641b5896cb0044cae577e
오늘 수업
https://teamsparta.notion.site/CPU-5fea015eb4654cf0a0234ab874424fb5
https://teamsparta.notion.site/CPU-5fea015eb4654cf0a0234ab874424fb5#cf1d1f5401e44293916119cb7383e67c
CPU
CPU는 메모리에 저장된 명령어를 읽어들이고, 해석하고, 실행하는 장치입니다.
그리고 CPU 내부에는 계산을 담당하는 ALU(산술 논리 연산 장치), 명령어를 읽어들이고 해석하는 제어 장치, 그리고 작은 임시 저장 장치인 레지스터라는 구성 요소가 있습니다.
ALU
ALU는 계산을 담당하는 부품입니다.
ALU는 계산을 담당하는 부품
ALU가 계산을 하기 위해서는 피연산자와 수행할 연산이 필요합니다.
그래서 ALU는 레지스터를 통해 피연산자를 받아들이고, 제어 장치로부터 수행할 연산을 알려주는 제어 신호를 받아들입니다.
ALU가 내보내는 정보
연산을 수행한 결과는 특정 숫자나 문자가 될 수도 있고, 메모리 주소가 될 수도 있습니다.
그리고 이 결과 값은 바로 메모리에 저장되지 않고 일시적으로 레지스터에 저장됩니다.
CPU가 메모리에 접근하는 속도는 레지스터에 접근하는 속도보다 훨씬 느립니다.
ALU가 연산할 때마다 결과를 메모리에 저장한다면, CPU는 메모리에 자주 접근하게 되고, 이는 CPU의 프로그램 실행 속도를 늦출 수 있습니다.
그래서 ALU의 결과 값을 메모리가 아닌 레지스터에 우선 저장하는 것입니다.
ALU는 계산 결과와 더불어 플래그를 내보냅니다.
때때로 ALU는 결과 값뿐만 아니라 연산 결과에 대한 추가적인 정보를 내보내야 할 때가 있습니다.
가령 연산 결과가 음수일 때, ALU는 '방금 계산한 결과는 음수'라는 추가 정보를 내보냅니다.
혹은 연산 결과가 연산 결과를 담을 레지스터보다 클 때, ALU는 '결과 값이 너무 크다'라는 추가 정보를 내보냅니다.
이러한 플래그는 CPU가 프로그램을 실행하는 도중 반드시 기억해야 하는 일종의 참고 정보입니다.
그리고 플래그들은 플래그 레지스터라는 레지스터에 저장됩니다.
플래그 레지스터는 이름 그대로 플래그 값들을 저장하는 레지스터입니다.
이 레지스터를 읽으면 연산 결과에 대한 추가적인 정보, 참고 정보를 얻을 수 있습니다.
이미지 :
예를 들어, 플래그 레지스터가 아래와 같은 구조를 가지고 있고, ALU가 연산을 수행한 직후 부호 플래그가 1이 되었다면 연산 결과는 음수임을 알 수 있습니다.
이미지
이미지들 사용하기
제어장치
제어 장치는 제어 신호를 내보내고 명령어를 해석하는 부품
제어 신호는 컴퓨터 부품들을 관리하고 작동시키기 위한 일종의 전기 신호
참고로, 제어 장치는 CPU의 구성 요소 중 가장 정교하게 설계된 부품이라고 해도 과언이 아닙니다.
그래서 CPU 제조사마다 제어 장치의 구현 방식이나 명령어를 해석하는 방식, 받아들이고 내보내는 정보에는 조금씩 차이가 있다.
이미지 :
1) 제어 장치는 클럭 신호를 받아들입니다.
클럭(clock)은 컴퓨터의 모든 부품을 움직일 수 있게 하는 시간 단위입니다.
클럭의 "똑딱-똑딱" 주기에 맞춰 한 레지스터에서 다른 레지스터로 데이터가 이동되거나, ALU에서 연산이 수행되거나, CPU가 메모리에 저장된 명령어를 읽어들이는 것입니다.
컴퓨터 부품들은 클럭이라는 박자에 맞춰 작동할 뿐, 한 박자마다 작동하는 것은 아닙니다.
하나의 명령어가 여러 클럭에 걸쳐 실행될 수도 있습니다.
2) 제어 장치는'해석해야 할 명령어'를 받아들입니다.
CPU가 해석해야 할 명령어는 '명령어 레지스터'라고 불리는 특별한 레지스터에 저장됩니다.
제어 장치는 이 명령어 레지스터에서 명령어를 받아들여 해석한 후, 제어 신호를 발생시켜 컴퓨터 부품들에게 수행할 작업을 지시합니다.
3) 제어 장치는 플래그 레지스터 속 플래그 값을 받아들입니다.
플래그는 ALU의 연산 결과에 대한 추가적인 상태 정보를 제공합니다.
제어 장치는 이러한 플래그 값을 고려하여 컴퓨터 부품들을 적절히 제어해야 합니다.
4) 제어 장치는 시스템 버스, 그 중에서 제어 버스로 전달된 제어 신호를 받아들입니다.
제어 신호는 CPU 내부의 부품뿐만 아니라 입출력 장치와 같은 CPU 외부 장치들을 조작할 때에도 사용됩니다.
제어 장치는 제어 버스를 통해 외부에서 오는 제어 신호도 받아들일 수 있습니다.
제어 장치가 내보내는 정보는 크게 두 가지로 나눌 수 있습니다
CPU 외부로 전달되는 제어 신호와 CPU 내부로 전달되는 제어 신호입니다.
제어장치가 있고 이거는 전기 신호로 실행 명령을 각 장치에 보낸다
CPU 외부로 전달되는 제어 신호는 주로 제어 버스를 통해 메모리와 입출력 장치로 보내집니다.
예를 들어, 메모리에 저장된 값을 읽거나 새로운 값을 저장하려 할 때, 제어 장치는 메모리에 제어 신호를 보냅니다.
입출력 장치의 값에 접근하거나 변경하고자 할 때도 마찬가지로 제어 신호가 필요합니다.
CPU 내부로 전달되는 제어 신호는 주로 ALU와 레지스터에 관련됩니다.
ALU에는 수행할 연산을 지시하는 제어 신호가, 레지스터에는 데이터 이동이나 명령어 해석을 위한 제어 신호가 전달됩니다.
이러한 제어 신호들은 CPU 내의 다양한 작업들을 조율하는 데 필수적입니다.
레지스터
프로그램의 명령어와 데이터는 실행 전후로 반드시 레지스터에 저장됩니다.
이는 레지스터에 저장된 값을 관찰함으로써 프로그램의 실행 흐름을 파악할 수 있음을 의미합니다.
즉, 레지스터 속의 값들을 유심히 관찰하면, 프로그램이 실행되는 동안 CPU 내에서 벌어지는 일들, 그리고 어떤 명령어가 어떻게 수행되는지 알 수 있습니다.
CPU 안에는 다양한 레지스터들이 존재하며, 각각 다른 역할을 가지고 있습니다.
이러한 레지스터들은 CPU의 작동과 프로그램 실행에 중요한 역할을 하며,
각각의 레지스터는 특정한 유형의 데이터나 명령어를 저장하고 처리하는 데 특화되어 있습니다.
예를 들어, 일부 레지스터는 연산 결과를 임시로 저장하거나, CPU가 다음에 실행할 명령어의 주소를 가리키는 데 사용됩니다.
이처럼 각 레지스터의 기능과 역할을 이해하는 것은 컴퓨터 구조와 프로그래밍의 중요한 부분입니다.
상용화된 CPU 속 레지스터들은 CPU마다 이름, 크기, 종류가 매우 다양합니다.
이들은 각 CPU 제조사의 홈페이지나 공식 문서 등에서 확인할 수 있습니다.
모든 레지스터를 전부 다룰 수는 없기에, 여러 전공 서적에서 중요하게 다루는 레지스터와 많은 CPU가 공통으로 포함하고 있는 주요 레지스터 네 가지를 알아보겠습니다.
1) 프로그램 카운터 (PC; Program Counter)
메모리에서 가져올 명령어의 주소, 즉 읽어들일 명령어의 주소를 저장합니다.
일부 CPU에서는 이를 '명령어 포인터 (Instruction Pointer)'라고 부르기도 합니다.
2) 명령어 레지스터 (Instruction Register)
방금 메모리에서 읽어들인, 해석할 명령어를 저장하는 레지스터입니다.
제어 장치는 이 레지스터의 명령어를 받아들이고 해석한 뒤 제어 신호를 내보냅니다.
3) 메모리 주소 레지스터 (MAR; Memory Address Register)
메모리의 주소를 저장하는 레지스터입니다.
CPU가 읽어들이고자 하는 주소 값을 주소 버스로 보낼 때 이 레지스터를 사용합니다.
4) 메모리 버퍼 레지스터 (MBR; Memory Buffer Register)
메모리와 주고받을 값(데이터와 명령어)을 저장하는 레지스터입니다.
메모리에 쓰고자 하는 값이나 메모리로부터 전달받은 값은 이 레지스터를 거칩니다.
명령어 싸이클과 인터럽트
'명령어 사이클' : CPU가 하나의 명령어를 처리하는 과정에는 정해진 흐름이 있으며, 이 흐름을 반복하면서 명령어들을 처리해 나가는 정형화된 흐름
명령어 사이클은 CPU가 명령어를 일관되고 체계적으로 처리하는 과정을 보장.
이 사이클은 명령어를 메모리에서 가져오는 단계, 해석하는 단계, 실행하는 단계로 구성됩니다.
과정이 완료되면 다음 명령어로 넘어갑니다.
인터럽트 : 때로는 CPU의 정해진 흐름이 끊어지는 상황이 발생하는 것
인터럽트는 시스템의 유연성을 제공하고 예외 상황에 신속하게 대응할 수 있도록 도와줌
예상치 못한 사건이나 요청이 발생했을 때 CPU에게 신호를 보내어 현재 진행 중인 작업을 일시 중단하고, 해당 사건이나 요청을 처리하도록 하는 메커니즘
하드웨어 인터럽트, 소프트웨어 인터럽트
이를 통해 CPU는 외부의 중요한 사건에 신속하게 반응하고, 더 효율적으로 시스템 자원을 관리할 수 있습니다.
명령어 사이클과 인터럽트는 CPU가 효율적으로 작동하고 다양한 상황에 대응할 수 있게 하는 핵심적인 개념입니다.
명령어 싸이클(instruction cycle)
클럭과는 다른 개념.
클럭은 하드웨어적으로 일정한 주기를 나타내기 위한 박자 같은 것
프로그램이 실행될 때, 그 안에 있는 수많은 명령어들은 CPU에 의해 하나씩 실행되는데 이때 프로그램 속 각각의 명령어들은 일정한 주기를 반복하며 실행되는 주기
인출 사이클(fetch cycle)
명령어 사이클의 첫 번째 과정
메모리에 저장된 명령어 하나를 실행한다고 가정해 볼 때, 가장 먼저 해야 할 일은 명령어를 메모리에서 CPU로 가져오는 것
실행 사이클(execution cycle)'
CPU로 명령어를 인출한 후에는 이제 명령어를 실행하는 단계로 넘어갑니다.
제어 장치가 명령어 레지스터에 담긴 값을 해석하고, 그에 따라 필요한 제어 신호를 발생시키는 단계가 실행 사이클
실행 프로그램을 이루는 수많은 명령어는 일반적으로 인출과 실행 사이클을 반복하며 실행됩니다.
즉, CPU는 프로그램 속 명령어를 가져오고 실행하고, 다시 가져오고 실행하는 과정을 반복하는 것입니다.
'간접 사이클(indirect cycle)'
명령어를 인출하여 CPU로 가져왔다 하더라도 곧바로 실행할 수 없는 경우 사용
ex)메모리 접근이 추가적으로 필요한 경우
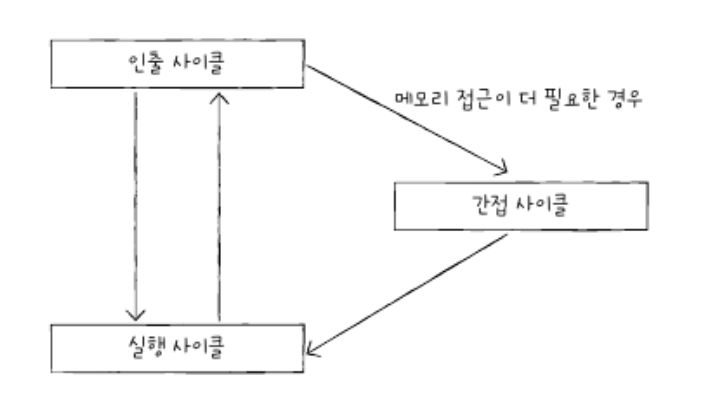
인터럽트
인터럽트(interrupt) : '방해하다, 중단시키다'
컴퓨터 시스템에서 인터럽트는 CPU가 수행 중인 작업을 잠시 중단시키는 신호를 의미
이 신호는 CPU가 현재 진행 중인 작업을 일시적으로 멈추고 다른 중요한 작업을 먼저 처리하도록 만듭니다.
인터럽트는 컴퓨터 시스템 내에서 긴급하거나 우선적으로 처리해야 할 상황을 알리는 역할을 합니다.
CPU가 작업을 잠시 중단해야 할 정도의 상황이라면, 인터럽트는 'CPU가 꼭 주목해야 할 때'나 'CPU가 긴급하게 처리해야 할 다른 작업이 생겼을 때' 발생합니다.
인터럽트의 발생 상황은 다양하며, 그 종류를 통해 구체적으로 어떤 상황에서 인터럽트가 발생하는지 이해할 수 있습니다.
인터럽트는 크게 동기 인터럽트와 비동기 인터럽트로 나뉩니다.
'예외(exception)' :동기 인터럽트(synchronous interrupt)
CPU가 명령어들을 수행하다가 예상치 못한 상황에 마주쳤을 때 발생.
예를 들어, 프로그래밍상의 오류나 예외적인 상황.
비동기 인터럽트(asynchronous interrupt)는 주로 입출력 장치에 의해 발생하는 인터럽트. 알림 역할
비동기 인터럽트(asynchronous interrupt)는 주로 입출력 장치에 의해 발생하는 인터럽트입니다.
입출력 장치에 의한 비동기 인터럽트는 세탁기 완료 알림이나 전자레인지 조리 완료 알림과 같은 알림 역할을 합니다.
예를 들어, CPU가 프린터와 같은 입출력 장치에 입출력 작업을 부탁하면, 작업을 끝낸 입출력 장치가 CPU에 완료 알림(인터럽트)을 보냅니다.
키보드나 마우스와 같은 입출력 장치가 어떠한 입력을 받아들였을 때 이를 처리하기 위해 CPU에 입력 알림(인터럽트)을 보내는 것도 포함됩니다.
따라서 비동기 인터럽트를 '하드웨어 인터럽트'라는 용어로 사용하기도 합니다.
인터럽트 서비스 루틴(Interrupt Service Routine, ISR) = 인터럽트 핸들러(interrupt handler)
다양한 유형의 인터럽트 요청에 대응하는 방법을 정의(미리 명시된 사항)
인터럽트 벡터(interrupt vector)
다양한 인터럽트 서비스 루틴을 구분하고 올바르게 처리하기 위해 사용.
인터럽트 벡터는 각 인터럽트에 해당하는 인터럽트 서비스 루틴의 시작 주소를 포함한 정보입니다.
이를 통해 CPU는 특정 인터럽트가 발생했을 때 해당 인터럽트 서비스 루틴을 식별하고, 그 시작 주소로 점프하여 인터럽트를 처리합니다.
인터럽트 처리 과정
1 입출력 장치는 CPU에 인터럽트 요청 신호를 보냅니다.
2 CPU는 실행 사이클이 끝나고 명령어를 인출하기 전에 항상 인터럽트 여부를 확인합니다.
3 CPU는 인터럽트 요청을 확인하고, 인터럽트 플래그를 통해 현재 인터럽트를 받아들일 수 있는지 여부를 확인합니다.
4 인터럽트를 받아들일 수 있다면, CPU는 현재의 작업을 백업합니다.
5 CPU는 인터럽트 벡터를 참조하여 인터럽트 서비스 루틴을 실행합니다.
6 인터럽트 서비스 루틴 실행이 끝나면, CPU는 백업해둔 작업을 복구하여 실행을 재개합니다.
인터럽트 사이클까지 포함한 명령어 사이클은 아래와 같습니다.

CPU 성능과 관련 있는 개념
클럭
빠른 CPU를 만들기
일반적으로 클럭 속도가 높아지면 CPU는 명령어 사이클을 더 빠르게 반복할 것이고, 다른 부품들도 그에 발맞춰 더 빠르게 작동.
클럭 속도는 헤르츠(Hz) 단위로 측정합니다. 이는 1초에 클럭이 몇 번 반복되는지를 나타냄
클럭 속도를 무작정 높이면 발열 문제가 더 심각진다.
클럭 속도를 높이는 것은 분명 CPU를 빠르게 만들지만, 클럭 속도만으로 CPU의 성능을 올리는 것에는 한계가 있다. -> 멀티코어 쓰는 이유
코어
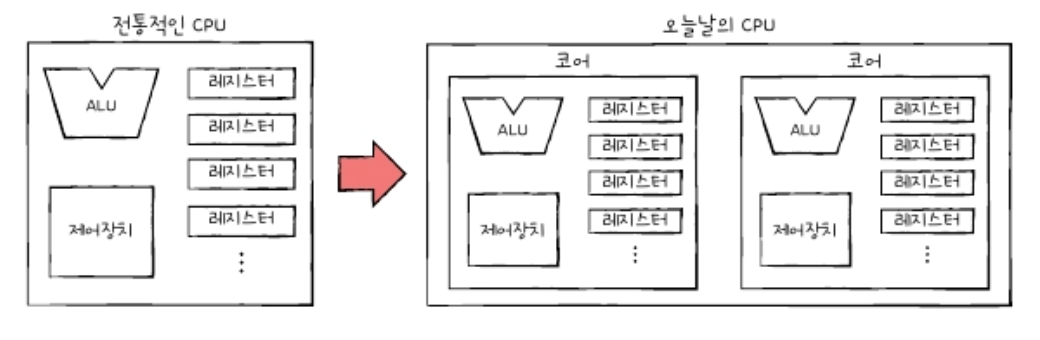
멀티코어(Multi-core) CPU 또는 멀티코어 프로세서
코어를 여러 개 포함하고 있는 CPU
CPU 종류는 CPU 안에 코어가 몇 개 포함되어 있는지에 따라 아래 표와 같이 싱글 코어, 듀얼 코어, 트리플 코어 등으로 나뉩니다.
멀티코어는 싱글코어보다 빠르지만 CPU의 연산 속도가 꼭 코어 수에 비례하여 증가하지는 않습니다.
중요한 것은 코어마다 처리할 명령어들을 얼마나 적절하게 분배하느냐이고 그에 따라서 연산 속도는 크게 달라집니다
스레드
CPU에서 사용되는 하드웨어적 스레드가 있고, 프로그램에서 사용되는 소프트웨어적 스레드
스레드의 하드웨어적 정의는 '하나의 코어가 동시에 처리하는 명령어 단위'를 의미하고, 소프트웨어적 정의는 '하나의 프로그램에서 독립적으로 실행되는 단위'를 의미
하드웨어적 스레드와 소프트웨어적 스레드는 구분하여 기억하는 것이 중요
스레드를 하드웨어적으로 정의하면 '하나의 코어가 동시에 처리하는 명령어 단위'를 의미합니다.
여러분이 CPU에서 사용하는 스레드라는 용어는 보통 CPU 입장에서 정의된 하드웨어적 스레드를 의미합니다.
우리가 지금까지 배운 CPU는 1 코어 1 스레드 CPU였습니다.
즉, 명령어를 실행하는 부품이 하나 있고, 한 번에 하나씩 명령어를 실행하는 CPU를 가정했지요.
반면, 여러 스레드를 지원하는 CPU는 하나의 코어로도 여러 개의 명령어를 동시에 실행할 수 있습니다.
예를 들어 2 코어 4 스레드 CPU는 명령어를 실행하는 부품을 두 개 포함하고, 한 번에 네 개의 명령어를 처리할 수 있는 CPU를 의미합니다.
이는 코어 하나당 두 개의 하드웨어 스레드를 처리한다는 뜻으로도 볼 수 있습니다.
8 코어 16 스레드는 명령어를 실행하는 부품을 여덟 개 포함하고, 한 번에 열여섯 개의 명령어를 처리할 수 있는 CPU를 의미하는 것이지요.
이번에는 소프트웨어적 스레드를 알아봅시다. 소프트웨어적으로 정의된 스레드는 '하나의 프로그램에서 독립적으로 실행되는 단위'를 의미합니다.
여러분이 프로그래밍 언어나 운영 체제를 학습할 때 접하는 스레드는 보통 이렇게 소프트웨어적으로 정의된 스레드를 의미합니다.
하나의 프로그램은 실행되는 과정에서 한 부분만 실행될 수도 있지만, 프로그램의 여러 부분이 동시에 실행될 수도 있습니다.
가령 여러분이 워드 프로세서 프로그램을 개발한다고 가정해보죠. 그리고 아래의 기능이 동시에 수행되길 원한다고 해봅시다.
사용자로부터 입력받은 내용을 화면에 보여주는 기능
사용자가 입력한 내용이 맞는지 검사하는 기능
사용자가 입력한 내용을 수시로 저장하는 기능
이 기능들을 작동시키는 코드를 각각의 스레드로 만들면 동시에 실행할 수 있습니다.
앞으로의 일정
1월 20일
메모리(1)
1월 22일
메모리(1)
1월 27일
운영체제 개요
1월 31일
프로세스와 스레드
컨텍스트 스위칭
2월 3일
레이스 컨디션과 동기화
가상 메모리
2월 5일
전체 Wrap-Up
'내일배움캠프_게임서버(202410) > 분반 수업 스텐다드' 카테고리의 다른 글
| 컴퓨터 구조 (1) | 2025.01.08 |
|---|---|
| 네트워크 (0) | 2025.01.06 |
| cpu 조사 (2) | 2025.01.03 |
| 전송계층 정리 241227 (1) | 2024.12.27 |
| 응용 계층(Application Layer) 조사 (0) | 2024.12.26 |




{kind=link}
{kind=link}
{kind=link}
{kind=link}