1. Subquery, Join 복습하기
Subquery
Query 결과를 Query 에 다시 활용하는 것
기본 형식
select column1, special_column
from
( /* subquery */
select column1, column2 special_column
from table1
) aJOIN
두 개 이상의 테이블을 결합하여 사용하는 것
기본 형식
-- LEFT JOIN
select 조회 할 컬럼
from 테이블1 a left join 테이블2 b on a.공통컬럼명=b.공통컬럼명
-- INNER JOIN
select 조회 할 컬럼
from 테이블1 a inner join 테이블2 b on a.공통컬럼명=b.공통컬럼명
데이터에서 예상하지 못한 값이 나왔을 때 (이상한 값, 값이 없음 등) 처리
02. 조회한 데이터에 아무 값이 없다면 어떻게 해야할까? - 데이터 가공
1) 데이터가 없을 때의 연산 결과 변화 케이스
▶ 테이블에 잘못된 값이 들어있을 수 있습니다. (ex)데이터 타입이 다른 데이터)
▶ JOIN 을 했을 때 값이 없는 경우 (left join 등)
사용할 수 없는 데이터가 들어있거나, 값이 없는 경우 처리방법
(데이터를 사용할 때 매우 흔한 경우입니다)
2) [방법1] 없는 값을 제외해주기
Mysql 에서는 사용할 수 없는 값일 때 해당 값을 연산에서 제외해줍니다. → 0으로 간주
즉 평균 rating 을 구하는 쿼리를 아래와 같이 작성했을 때 실제 연산에 사용되는 데이터는 다음과 같습니다.
select restaurant_name,
avg(rating) average_of_rating,
avg(if(rating<>'Not given', rating, null)) average_of_rating2
-- <> : 부정 rating<>'Not given' : rating은'Not given'이 아니다
from food_orders
group by 1if(rating<>'Not given', rating, null) : rating의 데이터가 'Not given'이 아니면 데이터 값을, 'Not given'이면 'null'을 적어줍니다,
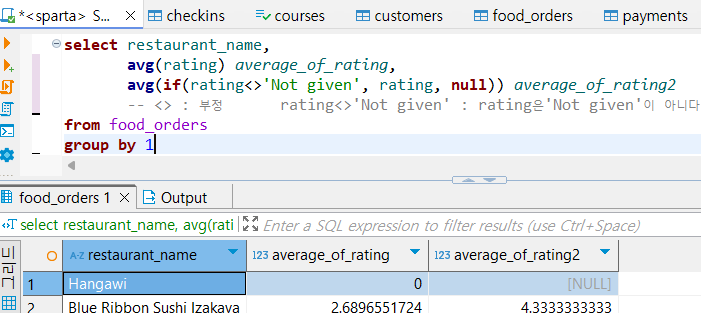
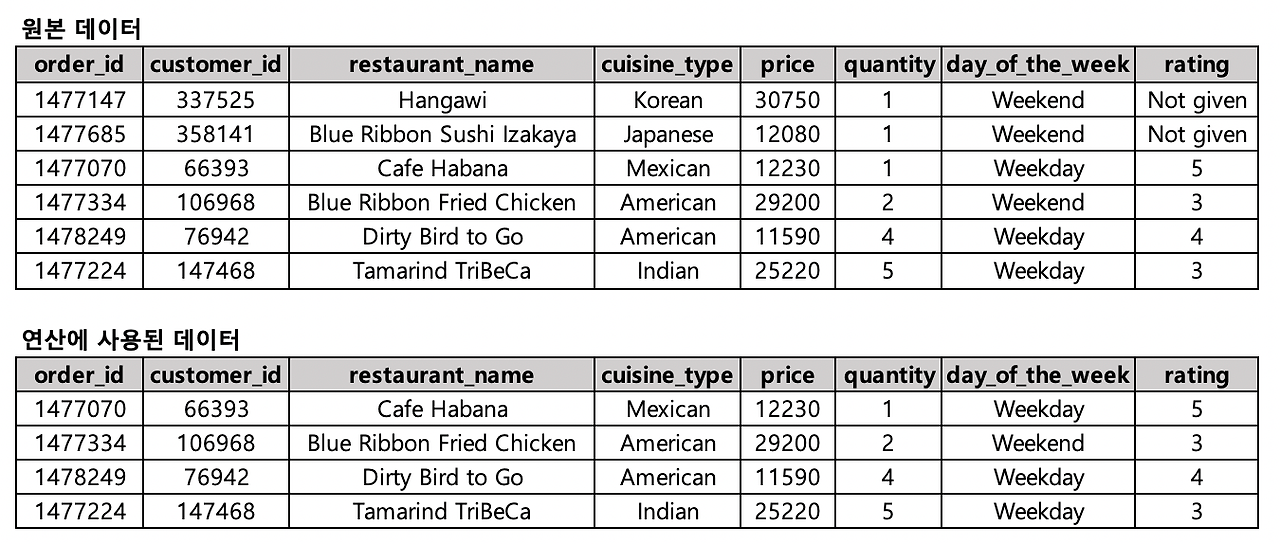
없는 자리는 0으로 취급하고 계산

값이 없는 자리를 제외하고 계산해서 위보다 price값이 큽니다.
따라서, 명확하게 연산을 지정해주기 위해 null 문법을 이용해봅시다.
-- 값의 제외
select a.order_id,
a.customer_id,
a.restaurant_name,
a.price,
b.name,
b.age,
b.gender
from food_orders a left join customers b on a.customer_id=b.customer_id
where b.customer_id is not null
null 제거를 하지 않았을 때

null 제거를 했을 때 (join 시에는 inner join 과 동일함)

3) [방법2] 다른 값을 대신 사용하기
사용할 수 없는 값 대신 다른 값을 대체해서 사용하는 방법이 있습니다.
데이터 분석 시에는 평균값 혹은 중앙값 등 대표값을 이용하여 대체해주기도 합니다.
다른 값으로 변경하고 싶을 때, 다음 두 개의 문법을 이용할 수 있습니다.
다른 값이 있을 때 조건문 이용하기 : if(rating>=1, rating, 대체값)
null 값일 때 : coalesce(age, 대체값)
null 을 다른 값으로 대체한 쿼리문을 실행하면 다음과 같습니다.
customer 테이블에 없는 데이터 중에 age 만 20으로 채워진 것을 확인하실 수 있습니다.
-- 값의 변경
select a.order_id,
a.customer_id,
a.restaurant_name,
a.price,
b.name,
b.age,
coalesce(b.age, 20) "null 제거",
b.gender
from food_orders a left join customers b on a.customer_id=b.customer_id
where b.age is null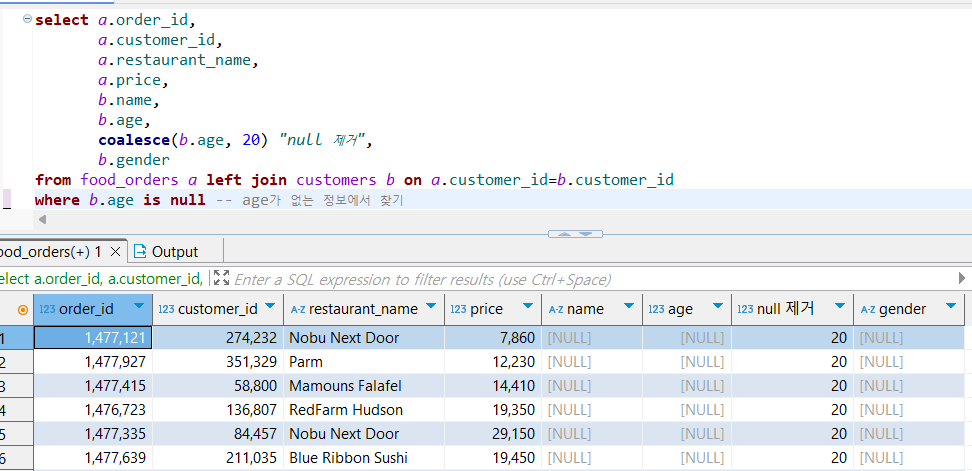
-- 컬럼에 값이 없는 경우 컬럼 "null 제거"에 대체데이터를 넣어줍니다.
coalesce(컬럼, 대체데이터) "null 제거",
03. 조회한 데이터가 상식적이지 않은 값을 가지고 있다면 어떻게 해야할까?
1) 상식적이지 않은 데이터의 예시
데이터가 비어있는 경우도 있지만, 상식적이지 않은 경우도 있습니다.
예시)
케이스1 - 주문 고객의 나이
보통 음식을 주문한 고객은 20세 이상인 성인인 경우가 많습니다. 하지만 데이터를 보면 2세와 같이 상식적이지 않은 값들을 확인할 수 있습니다.

케이스2 - 결제 일자
결제의 경우, 비교적 최근인 일자가 있어야 상식적일 것입니다. 하지만, 데이터를 보면 1970년대와 같이 상식적이지 않은 값들을 확인할 수 있습니다.
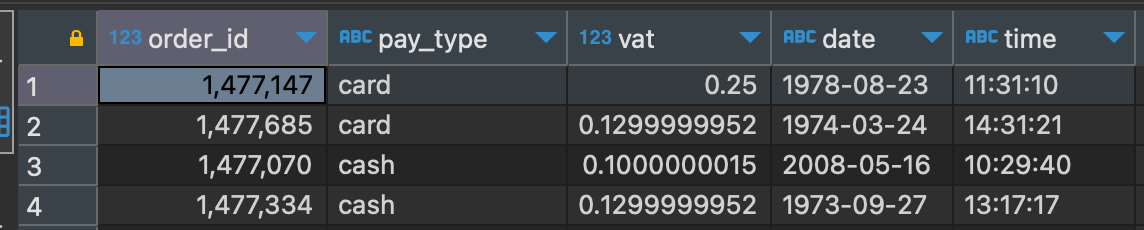
2) [방법] 조건문으로 값의 범위를 지정하기
조건문으로 가장 큰 값, 가장 작은 값의 범위를 지정해 줄 수 있습니다.
→ 상식적인 수준 안에서 범위를 지정해줍니다.
위의 나이의 경우 아래와 같은 범위를 지정해 줄 수 있습니다.
select customer_id, name, email, gender, age,
case when age<15 then 15
when age>80 then 80
else age end "범위를 지정해준 age"
from customers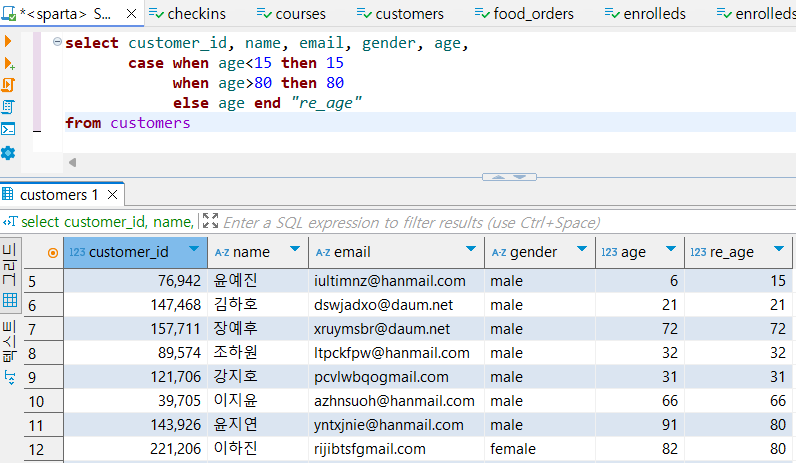
범위를 지정해준 결과, 15세 미만이거나 80세 초과인 경우 15, 80으로 각각 대체된 것을 확인할 수 있습니다.
SQL 로 엑셀에서 자주 사용하는 형태로 데이터를 만든다
04. [실습] SQL 로 Pivot Table 만들어보기
데이터를 뽑아서 엑셀로 가공하지 않고, 바로 Pivot table 을 만드는 방법을 알아봅시다
1) Pivot table 구조 소개
Pivot table 이란? : 2개 이상의 기준으로 데이터를 집계할 때, 보기 쉽게 배열하여 보여주는 것을 의미합니다
Pivot table 의 기본 구조

Pivot table 의 예시
집계 기준 : 일자, 시간

2) [실습] 음식점별 시간별 주문건수 Pivot Table 뷰 만들기 (15~20시 사이, 20시 주문건수 기준 내림차순)
음식점별, 시간별 주문건수 집계하기
// from으로 조회할 테이블 만들기
select a.restaurant_name,
substring(b.time, 1, 2) hh,
count(1) cnt_order
from food_orders a inner join payments b on a.order_id=b.order_id
where substring(b.time, 1, 2) between 15 and 20
group by 1, 2
Pivot view 구조 만들기
Pivot Table 예시
select restaurant_name,
-- 컬럼을 한줄 씩 추가
max(if(hh='15', cnt_order, 0)) "15",
max(if(hh='16', cnt_order, 0)) "16",
max(if(hh='17', cnt_order, 0)) "17",
max(if(hh='18', cnt_order, 0)) "18",
max(if(hh='19', cnt_order, 0)) "19",
max(if(hh='20', cnt_order, 0)) "20"
-- 위쪽이 실질적인 Pivot table
from
(
select a.restaurant_name,
substring(b.time, 1, 2) hh,
count(1) cnt_order
from food_orders a inner join payments b on a.order_id=b.order_id
where substring(b.time, 1, 2) between 15 and 20
group by 1, 2
) a
group by 1
order by 7 desc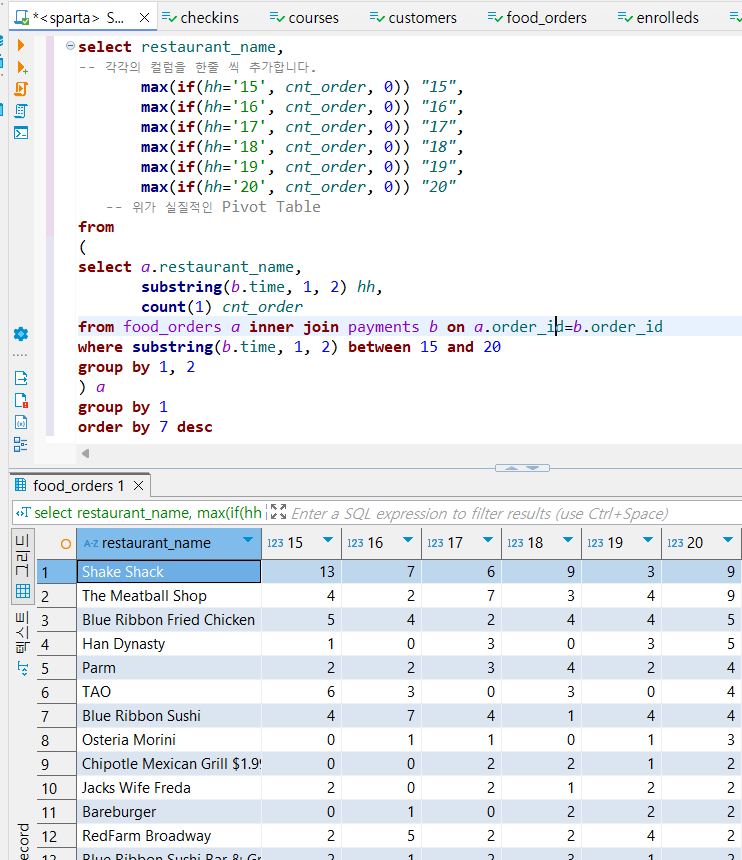
3) [실습] 성별, 연령별 주문건수 Pivot Table 뷰 만들기 (나이는 10~59세 사이, 연령 순으로 내림차순)
성별, 연령별 주문건수 집계하기
select b.gender,
case when age between 10 and 19 then 10
when age between 20 and 29 then 20
when age between 30 and 39 then 30
when age between 40 and 49 then 40
when age between 50 and 59 then 50 end age,
count(1)
from food_orders a inner join customers b on a.customer_id=b.customer_id
where b.age between 10 and 59
group by 1, 2
Pivot view 구조 만들기
select age,
max(if(gender='male', order_count, 0)) male,
max(if(gender='female', order_count, 0)) female
from
(
select b.gender,
case when age between 10 and 19 then 10
when age between 20 and 29 then 20
when age between 30 and 39 then 30
when age between 40 and 49 then 40
when age between 50 and 59 then 50 end age,
count(1) order_count -- 주문건수
from food_orders a inner join customers b on a.customer_id=b.customer_id
where b.age between 10 and 59
group by 1, 2
) t
group by 1
order by age
업무에 활용할 수 있는 다양한 SQL 심화 문법을 익힌다
05. 업무 시작을 단축시켜 주는 마법의 문법 (Window Function - RANK, SUM)
1) Window Function (윈도우 함수)의 사례와 기본 구조
◆ Window Function 은 각 행의 관계를 정의하기 위한 함수로 그룹 내의 연산을 쉽게 만들어줍니다.
예시) 뭉터기별 합계가 필요할
▷ 한식 식당 중에서 주문건수가 많은 순으로 순위를 매기고 싶은데요, 가능할까요?
▷ 한식 식당 전체 주문건수 중에서 A 식당이 차지하는 비율을 알고 싶은데 가능할까요?
▷ 2건 이상 주문을 한 소비자 중에, 처음 주문한 식당과 2번째로 주문한 식당을 같이 조회할 수 있을까요?
◆ 기본 SQL 구조로 해결하기 위해서는 복잡하게 Subquery 문을 이용하거나, 여러번의 연산을 수행해줘야 하지만, 자체적으로 제공해주는 기능을 이용하면 조금 더 편리합니다.
→ 바로 이 기능들이 Window function 으로 제공되고 있습니다.
◆ Window Function 의 기본 구조
window_function(argument) over (partition by 그룹 기준 컬럼 order by 정렬 기준)
window_function : 기능 명을 사용해줍니다. (sum, avg 와 같이 기능명이 있습니다)
argument : 함수에 따라 작성하거나 생략합니다.
partition by : 그룹을 나누기 위한 기준입니다. group by 절과 유사하다고 생각해주시면 됩니다.
order by : window function 을 적용할 때 정렬 할 컬럼 기준을 적어줍니다.
2) [실습1] N 번째까지의 대상을 조회하고 싶을 때, Rank 함수
Rank() 는 ‘특정 기준으로 순위를 매겨주는’ 기능입니다.
rank() over (partition by 그룹 기준 컬럼 order by 정렬 기준)
예를 들어, 주문 건수별 순위 매기기, 결제 시간이 빠른 순으로 순위 매기기 등이 가능합니다.
[실습] 음식 타입별로 주문 건수가 가장 많은 상점 3개씩 조회하기
1. 음식 타입별, 음식점별 주문 건수 집계하기
select cuisine_type, restaurant_name, count(1) order_count
from food_orders
group by 1, 2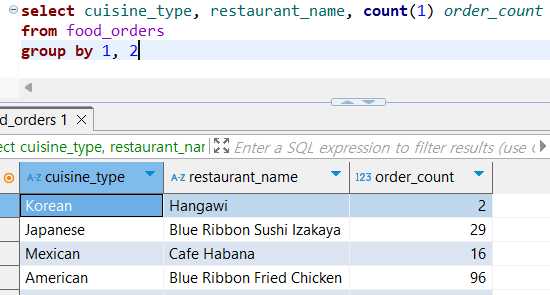
2. Rank 함수 적용하기
select cuisine_type,
restaurant_name,
rank() over (partition by cuisine_type order by order_count desc) rn,
-- rank()의 괄호 안은 비워둡니다.
order_count
from
(
select cuisine_type, restaurant_name, count(1) order_count
from food_orders
group by 1, 2
) a
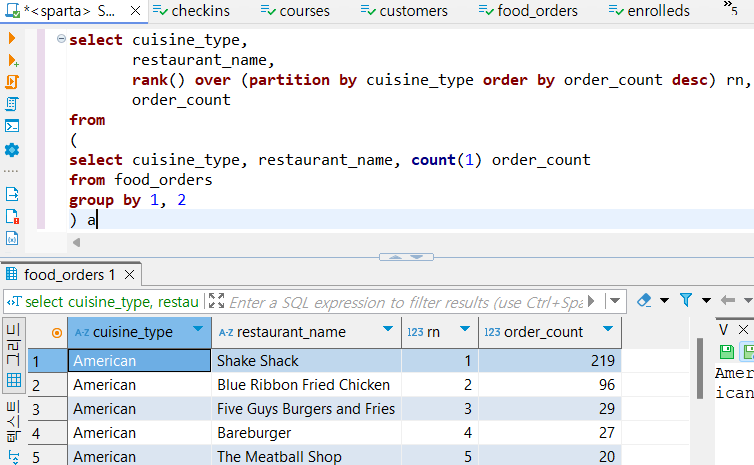
3. cuisine_type별로 3위까지 조회하고, 음식 타입별, 순위별로 정렬하기
select cuisine_type,
restaurant_name,
order_count,
rn "순위"
from
(
select cuisine_type,
restaurant_name,
rank() over (partition by cuisine_type order by order_count desc) rn,
order_count
from
(
select cuisine_type, restaurant_name, count(1) order_count
from food_orders
group by 1, 2
) a
) b
where rn<=3
order by 1, 4
3) [실습2] 전체에서 차지하는 비율, 누적합을 구할 때, Sum
sum(컬럼명) over (partition by 그룹기준 컬럼)
sum(컬럼명) over (partition by 그룹기준 컬럼 order by 정렬기준 컬럼)
Sum 은 앞서 배운 합계를 구하는 기능과 동일합니다.
다만, 누적합이 필요하거나 카테고리별 합계컬럼와 원본 컬럼을 함께 이용할 때 유용하게 사용할 수 있습니다.
[실습] 각 음식점의 주문건이 해당 음식 타입에서 차지하는 비율을 구하고, 주문건이 낮은 순으로 정렬했을 때 누적 합 구하기
음식 타입별, 음식점별 주문 건수 집계하기
select cuisine_type, restaurant_name, count(1) order_count
from food_orders
group by 1, 2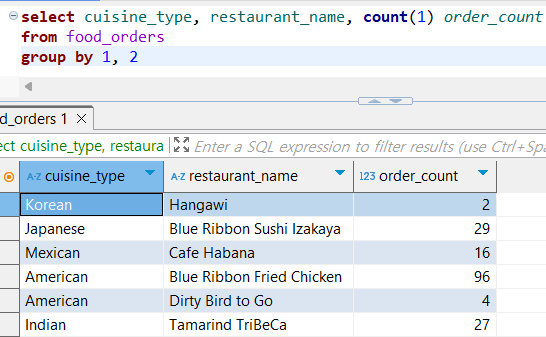
카테고리별 합, 카테고리별 누적합 구하기
select cuisine_type,
restaurant_name,
cnt_order,
sum(cnt_order) over (partition by cuisine_type) sum_cuisine,
sum(cnt_order) over (partition by cuisine_type order by cnt_order) cum_cuisine
from
(
select cuisine_type,
restaurant_name,
count(1) cnt_order
from food_orders
group by 1, 2
) a
order by cuisine_type , cnt_order
누적합 고쳐보기
위 정답에서 order_count가 동일한 값을 일괄로 더해 cum_sum으로 출력되는 문제가 있었어요.
문제 상황 이해
이 상황은 SQL에서 WINDOW 함수(SUM 등)를 사용할 때, SUM으로 동일한 cnt_order 값을 가진 여러 행이 있을 경우, SQL 엔진은 이 값을 한꺼번에 더하는 현상이 발생합니다. cnt_order의 순서를 결정할 명확한 기준이 없으므로 발생한 문제입니다.
해결 방법
이 문제를 해결하려면 ORDER BY 절에 cnt_order 외에 추가적인 열에 순서를 부여할 수 있는 restaurant_name을 포함시켜야 합니다. 이렇게 하면 동일한 cnt_order 값을 가진 행들이 명확하게 순서가 정해져 누적합이 정상적으로 처리됩니다.
누적합을 순서대로 표기하기 위해 order by에 cum_cuisine 을 추가해줍니다.
select cuisine_type,
restaurant_name,
cnt_order,
sum(cnt_order) over (partition by cuisine_type) sum_cuisine,
sum(cnt_order) over (partition by cuisine_type order by cnt_order, restaurant_name) cum_cuisine
from
(
select cuisine_type,
restaurant_name,
count(1) cnt_order
from food_orders
group by 1, 2
) a
order by cuisine_type , cnt_order, cum_cuisine
이 외의 Window Function 을 알고 싶다면, 여러가지를 검색해서 사용해보는 것을 추천합니다
06. 날짜 포맷과 조건까지 SQL 로 한 번에 끝내기 (포맷 함수)
데이터에 날짜를 지정하거나 조건에 날짜를 사용해야할 때 활용할 수 있는 기능을 알아봅시다
1) 날짜 데이터의 이해 (컬럼의 데이터타입 기호 : 시계모양)

◆ 문자타입, 숫자타입과 같이 날짜 데이터도 특정한 타입을 가지고 있습니다.
◆ 년, 월, 일, 시, 분, 초 등의 값을 모두 갖고 있으며 목적에 따라 ‘월’, ‘주’, ‘일’ 등으로 포맷을 변경할 수도 있습니다.
아래와 같은 형식의 데이터라면 날짜로 변경 가능합니다.
2) [실습1] 날짜 데이터의 여러 포맷
yyyy-mm-dd 형식의 컬럼을 date type 으로 변경하기
select date(date) date_type, -- 함수명(컬럼명) 컬럼명부여
date
from payments
date type 을 date_format 을 이용하여 년, 월, 일, 주 로 조회해보기
년 : Y (4자리), y(2자리)
월 : M, m
일 : d, e
요일 : w
날짜 예시
select date(date) date_type,
-- 데이터타입_format(컬럼, 추출할것)
date_format(date(date), '%Y') "년", -- 날짜 형식의 데이터에서 년도만 남기기
date_format(date(date), '%m') "월",
date_format(date(date), '%d') "일",
date_format(date(date), '%w') "요일" -- 데이트포멧은 몇주차인지, 무슨 요일인지도 가져올 수 있음
-- 1은 월요일, 3인 수요일
from payments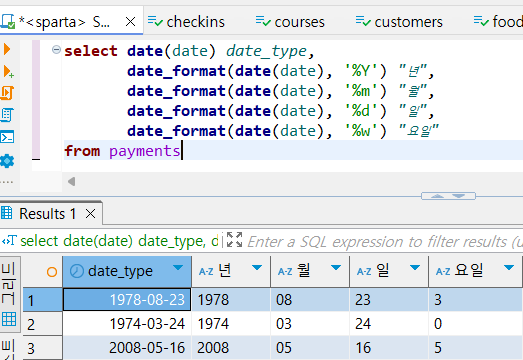
4) [실습2]
년도, 월을 포함하여 데이터 가공하기
select date_format(date(date), '%Y') y,
date_format(date(date), '%m') m,
date_format(date(date), '%y.%m') ym,
a.order_id
from food_orders a inner join payments b on a.order_id=b.order_id
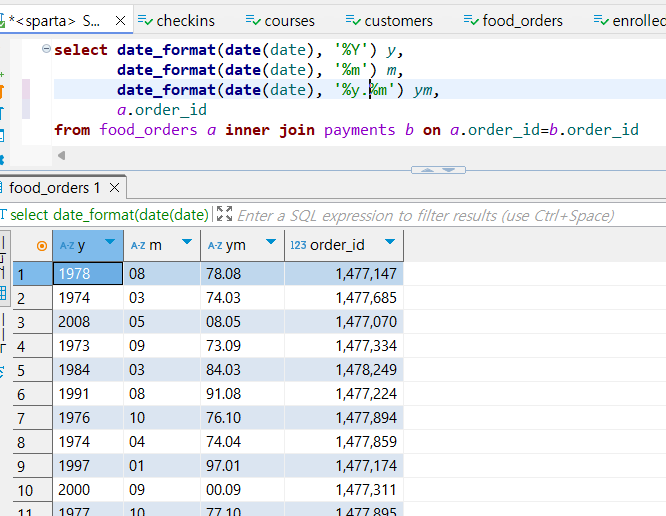
date_format(date(date), '%y.%m') ym -- '%y.%m'처럼 중간에 넣은 기호가 적용 됩니다.
년도, 월별 주문건수 구하기
select date_format(date(date), '%Y') y,
date_format(date(date), '%m') m,
count(1) order_count
from food_orders a inner join payments b on a.order_id=b.order_id
group by 1, 2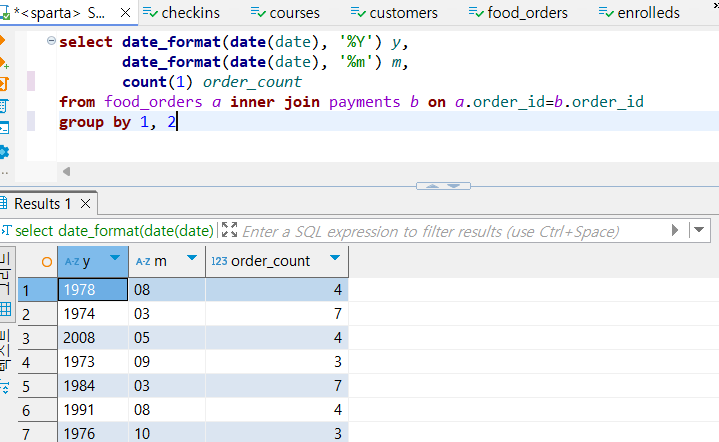
3월 조건으로 지정하고, 년도별로 정렬하기
select date_format(date(date), '%Y') y,
date_format(date(date), '%m') m,
count(1) order_count
from food_orders a inner join payments b on a.order_id=b.order_id
where date_format(date(date), '%m')='03'
group by 1, 2
order by 1
숙제
문제 : 음식 타입별, 연령별 주문건수 pivot view 만들기
[지시사항]
음식 타입별, 연령별 주문건수 pivot view 만들기 (연령은 10~59세 사이)
1. SQL 기본구조 작성하기
흐름 정리
어떤 테이블에서 데이터를 뽑을 것인가
음식 주문, 고객 테이블 -> food_orders, custermers 테이블
어떤 컬럼을 이용할 것인가
공통 : customer_id
출력 : 음식점타입, 고객 연령 -> f.cuisine_type , c.age
어떤 조건을 지정해야 하는가 X
어떤 함수 (수식) 을 이용해야 하는가
max(if( )

오답 pivot table 만드는 방법으로 해야함
2. Pivot view 를 만들기 위해 필요한 데이터 가공하기
select f.cuisine_type 'cuisine_type', c.age 'age'
from food_orders f inner join customers c on f.customer_id = c.customer_id
3. Pivot view 문법에 맞추어 수정하기
select cuisine_type,
count(case when age between 10 and 19 then 1 end) '10대',
count(case when age between 20 and 29 then 1 end) '20대',
count(case when age between 30 and 39 then 1 end) '30대',
count(case when age between 40 and 49 then 1 end) '40대',
count(case when age between 50 and 59 then 1 end) '50대'
from(
select f.cuisine_type 'cuisine_type', c.age 'age'
from food_orders f inner join customers c on f.customer_id = c.customer_id
)a
group by 1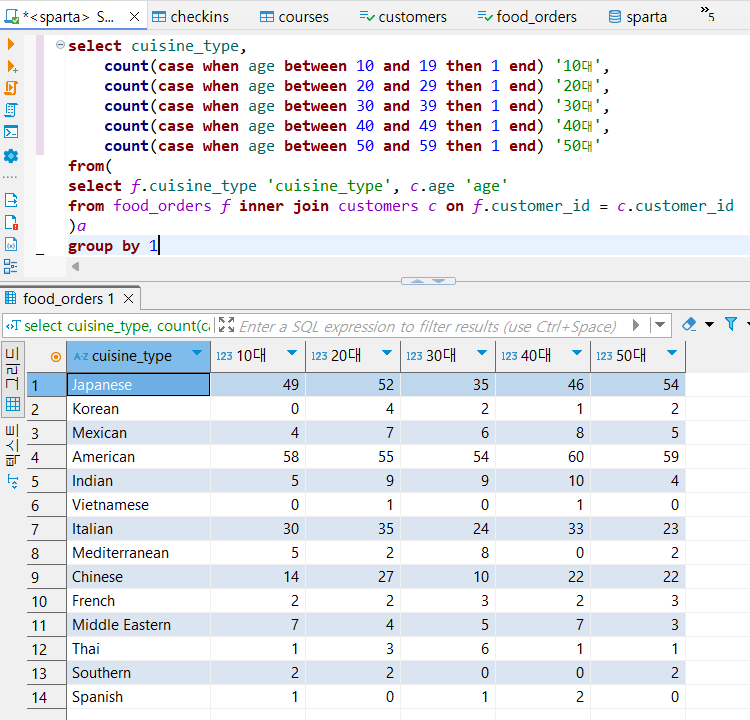
2. Pivot view 를 만들기 위해 필요한 데이터 가공하기
select f.cuisine_type 'cuisine_type',
case when age between 10 and 19 then '10대'
when age between 20 and 29 then '20대'
when age between 30 and 39 then '30대'
when age between 40 and 49 then '40대'
when age between 50 and 59 then '50대' end new_age,
count(1) cnt_age
from food_orders f inner join customers c on f.customer_id = c.customer_id
group by 1,2
3. Pivot view 문법에 맞추어 수정하기
select cuisine_type,
max(if(new_age='10대', cnt_age, 0)) "10대",
max(if(new_age='20대', cnt_age, 0)) "20대",
max(if(new_age='30대', cnt_age, 0)) "30대",
max(if(new_age='40대', cnt_age, 0)) "40대",
max(if(new_age='50대', cnt_age, 0)) "50대"
from(
select f.cuisine_type 'cuisine_type',
case when age between 10 and 19 then '10대'
when age between 20 and 29 then '20대'
when age between 30 and 39 then '30대'
when age between 40 and 49 then '40대'
when age between 50 and 59 then '50대' end new_age,
count(1) cnt_age
from food_orders f inner join customers c on f.customer_id = c.customer_id
group by 1,2
)a
group by 1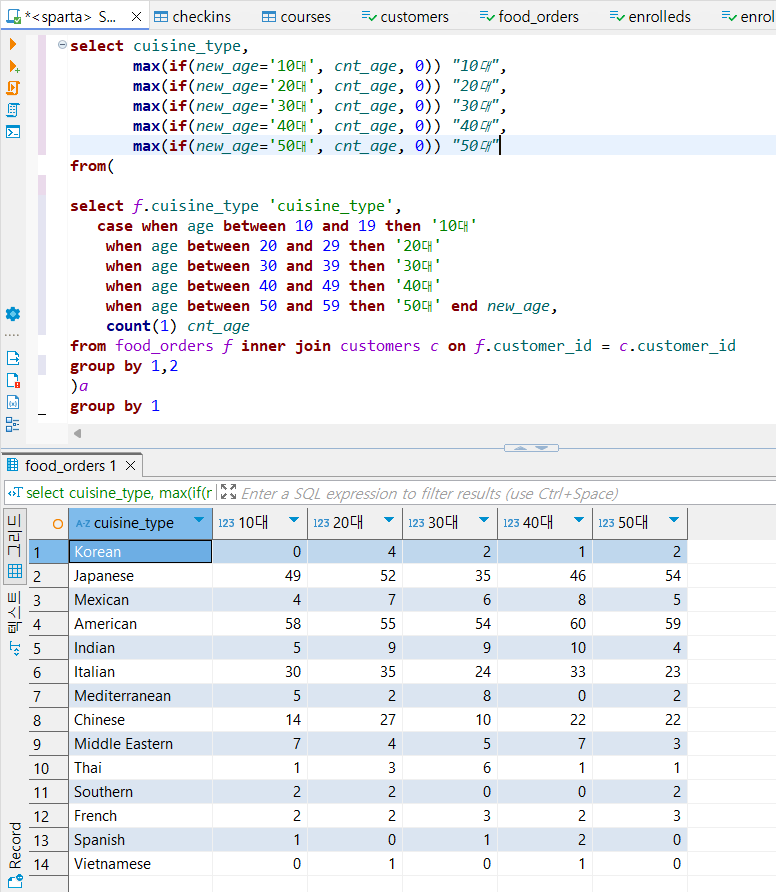
※ 요약
◆ Null 및 이상 값 처리 ( 데이터가 없을 때의 연산 결과 변화)
▷ 특정 컬럼 값이 없을 경우, `coalesce()`로 대체 값을 넣거나 `if()`문을 사용해 값이 없는 경우 다른 값을 넣음.
다른 값이 있을 때 조건문 이용하기 : if(rating>=1, rating, 대체값)
null 값일 때 : coalesce(age, 대체값) where 컬럼명 is not null -- where로 지정 컬럼에 null데이터가 아닌 데이터만 가져오기
▷ 이상 값(나이가 999살, 사람 키가 3m 같은) 처리
- 조건문을 사용하여 값의 범위를 제한해줌.
◆ Pivot Table 생성
Pivot View : 집계 기준을 행과 열로 나눠 데이터 집계.
서브쿼리에서 다 만들어 놓고 해당하는 걸 위에서 컬럼으로 만들기
max(if(컬럼1="일치값", 데이터 가져올컬럼, 0)) "만들컬럼이름"Pivot Table 예시
select restaurant_name,
-- 컬럼을 한줄 씩 추가
max(if(hh='15', cnt_order, 0)) "15",
max(if(hh='16', cnt_order, 0)) "16",
max(if(hh='17', cnt_order, 0)) "17",
max(if(hh='18', cnt_order, 0)) "18",
max(if(hh='19', cnt_order, 0)) "19",
max(if(hh='20', cnt_order, 0)) "20"
-- 위쪽이 실질적인 Pivot table
from (서브쿼리) a
group by 1
order by 7 desc
◆ Window Function (윈도우 함수)
- 특정 기준으로 정렬하여 순위 계산, 누적합 등 다양한 통계를 그룹 내에서 쉽게 처리.
Window Function 의 기본 구조
window_function(argument) over (partition by 그룹 기준 컬럼 order by 정렬 기준)
window_function : 기능 명을 사용해줍니다. (sum, avg 와 같이 기능명이 있습니다)
argument : 함수에 따라 작성하거나 생략합니다.
partition by : 그룹을 나누기 위한 기준입니다. group by 절과 유사하다고 생각해주시면 됩니다.
order by : window function 을 적용할 때 정렬 할 컬럼 기준을 적어줍니다.
▷ Rank 함수
Rank() 는 ‘특정 기준으로 순위를 매겨주는’ 기능입니다.
rank() over (partition by 그룹 기준 컬럼 order by 정렬 기준)
select rank() over (partition by cuisine_type order by order_count desc)
▷ 날짜 포맷과 조건까지 SQL 로 한 번에 끝내기 (포맷 함수)
`date_format()`을 사용해 날짜 컬럼에서 특정 단위(년, 월 등)로 데이터를 가공.
년 : Y (4자리), y(2자리)
월 : M, m
일 : d, e
요일 : w

※Tip
◆ 쿼리문 작성 시 2줄 이상 띄우면 서로 다른 쿼문장으로 이해합니다.
실행시키면 커서의 위치에 있는 쿼리문이 실행됩니다.
'내일배움 강의 > 완강 - 엑셀보다 쉽고 빠른 SQL' 카테고리의 다른 글
| 0 _ Dbeaver (1) | 2024.12.02 |
|---|---|
| SQL - 4주차 (2) | 2024.11.19 |
| SQL - 3주차 (1) | 2024.11.12 |
| SQL - 2주차 (1) | 2024.11.01 |
| SQL - 1주차 (1) | 2024.10.30 |



